Apologies and yet without apology
Apologies up front as the subject of this blog post is both n00bie-ish as well as somewhat advanced and awfully, awfully, awfully important. It’s super-duper important that you understand what follows because a common design requirement and an equally common design solution won’t and doesn’t take into account OneStream’s core storage model. I’ll be making references to Data Management jobs, Finance business rules, as well as Data Buffer processing which is all rather a lot for a n00b post. But all of that is exposition – the key thing for we n00bs is to understand that a design approach we all take for granted in other tools is a Bad Idea in OneStream. Happily, the solution is straightforward.
The 42 people who regularly read this blog probably know a fair bit – although logic demands that I ask why you lucky 42 read it if you already know it. Perhaps you enjoy irrelevant links to popular culture from a year that predates your time on this planet by at least 50 years. Ask your parents or better yet your grandparents to help with that sort of confusion; hopefully the balance of the post will make sense by the end for my August Audience. And with that Gentle Reader, let’s begin.
The use case
We happy few (actually not so few – planning-with-a-p is quite the thing in OneStream applications) typically want to keep versions of budgets, forecasts, projections, etc. It seems logical in a multidimensional world to accomplish that by creating a Version dimension and storing that generation of data in said member.
Don’t
Do
That
Why shouldn’t I?
Because reasons. What reasons? The Data Unit is why.
Storing and accessing
A Data Unit is OneStream’s primary organizer of data. It consists of: Cube, Entity, Scenario, Cons, and Time. When a Finance Business Rule (or other fantabulous engine – there are quite a few of them) executes a process, it considers and evaluates every record (remember that data is relationally stored) that matches that logical key (Time is in the columns so it doesn’t act as a true key but it is part of the data evaluation process and actually the UDs are part of the key but in a hashed fashion and now we have gone WAY too far into the weeds) and then processes it in memory. Oh sure, your user defined (UD) dimensions can be filtered by their members in a (for instance) Finance Business Rule Data Buffer but all of the relational records that match that Data Unit are evaluated for processing even if you only care about a subset.
Sometimes that wide scope of data is required but if it isn’t, why bother?
Less is more
Ludwig Mies Van Der Roh had it right when it comes to performance: fewer records to process means faster performance. This is true for every system and tool I’ve worked with and it makes sense: there is simply less to do. No, this isn’t your excuse to write lousy code; only Yr. Obt. Svt. does that and hopefully only within the context of this blog, but it is a design concept to consider if you care at all about performance and of course you do. Don’t you? Yes, of course you do.
Unpossible, but true
As an aside, I have somewhat unbelievably been on projects where potential performance was all but ignored and not by me. Again, Don’t Do That as Nothing Good can stem from impersonating ostriches.
That sea of data
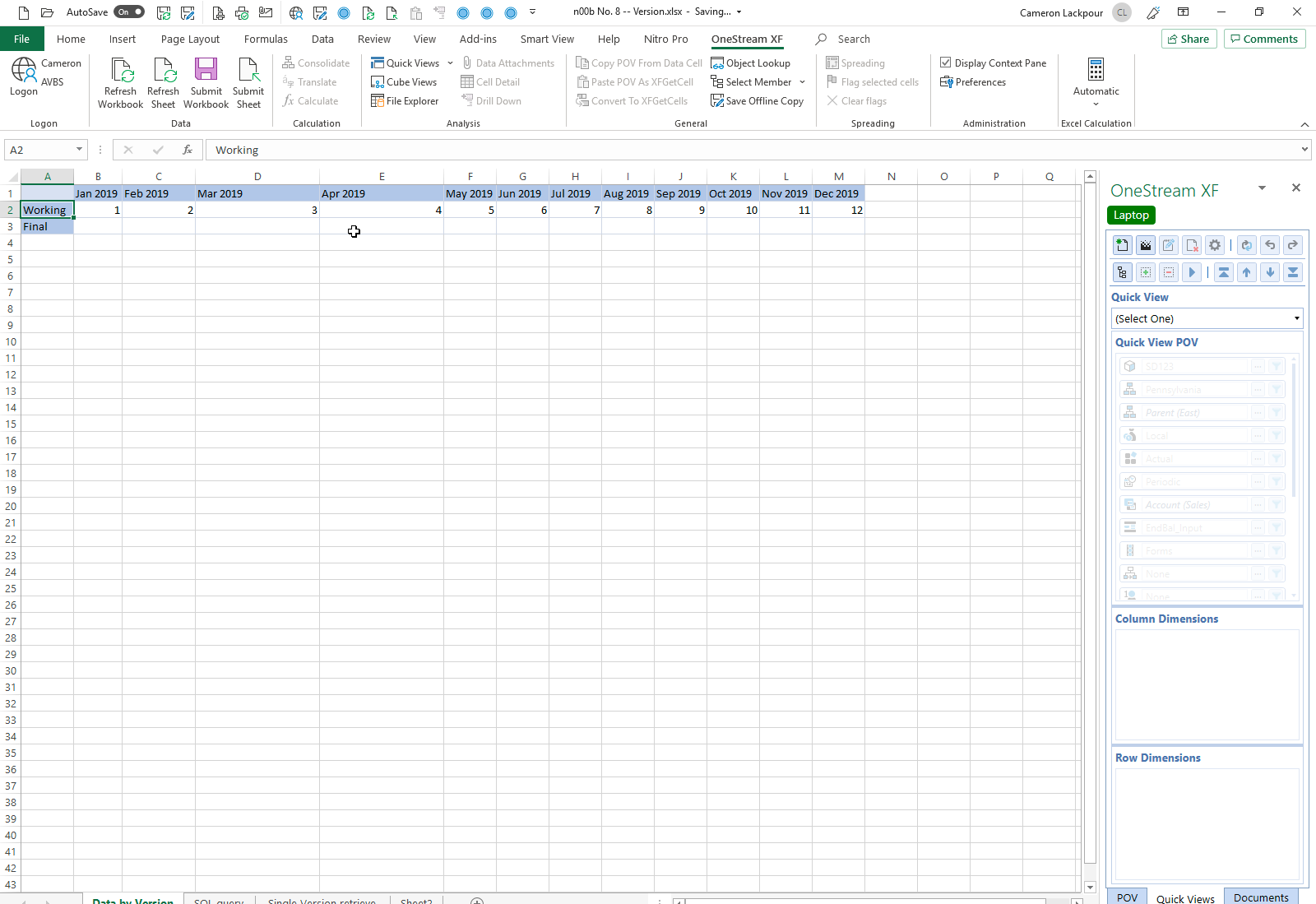
Let’s talk about data – actually *no* data except for one itsy bitsy 12 months of data. The example I’ll use resides in a totally empty copy of AVBS save for the Keystone State’s single row of data.
How do we get that in? From a simple send from a QuickView.
Unpossible, but true, part the second
So long as I’m opining (as if I ever stop) there seems to be a subset of those who believe that Excel and OneStream are some kind of (un)necessary evil as who on earth would ever want to analyze data in Excel. The first time I heard this I was somewhat taken aback, bemused, and befuddled. I know you, Gentle Reader, understand the value that Excel brings to any EPM application.
Yes, OneStream has CubeViews and yes the OneStream Windows client has a spreadsheet component but nothing beats the innate flexibility and power of Excel for ad hoc analysis. Nothing. Use it.
Phew. Two rants in one blog post. I am on fire today.
What’s actually there?
Desperately clawing my way back to something you might actually care about, here’s Yr. Obt. Svt. writing the crap SQL he is inordinately proud of:
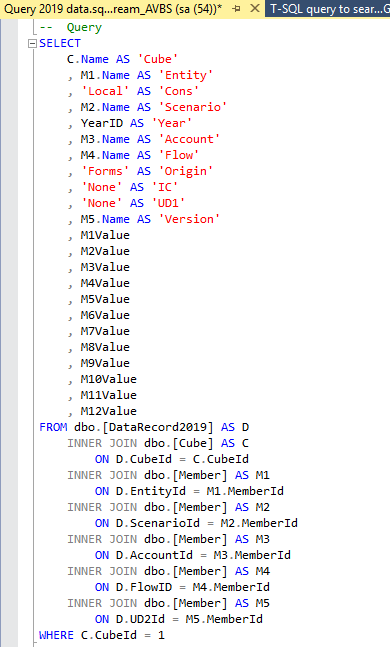
Not that you’ll ever have to write or read or care overmuch about raw SQL against source data tabes to use the product but if you’re like me and desperately need another hobby, the above query will give show just exactly what’s stored in the data tables in a form that humans can actually understand as I’ve JOINed to the relevant descriptive tables. Again, we’re down in the guts of the product and only total n00b losers really intelligent, handsome, and good-to-their-mothers tippy-top sorts of chaps and chapettes care about this stuff. That’s you, innit? Also, I’d note that this completely ignores security, Workflow, data integrity, and the American Way. Not to worry as except on a laptop install it isn’t likely that you’ll have access and it’s more likely that I’ll be reincarnated as an olive than your users ever seeing it. Remember, this is for Educational Purposes Only.
Whew.
What do we get with just one record?

A bit hard to read but we can see the Cube, Entity, Parent, Cons, Scenario, and Time data that make up the Data Unit as well as all of the other dimensions as well as — wait for it — UD2/Version.
Skip over UD1 (one day, soon, I will bore you to death with great savoir faire explain why There Is No Cube and why that’s a Good Thing) as this cube doesn’t use it and focus on the UD2 Version column. Note that it contains the value “Working”.
And then note this Data Management Custom Calculate step:
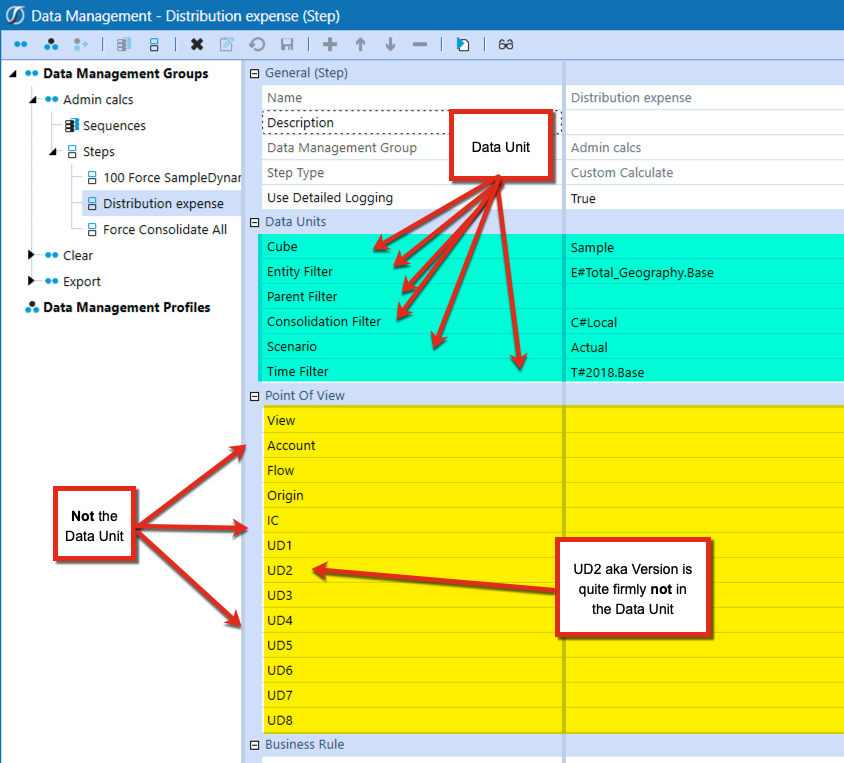
US2 does not define the Data Unit which means that there is no way for OneStream to evaluate just the data with a value of “Working”. Instead it’ll process all of the data in the data unit even when only the “Working” data is relevant.
Yet another aside
I note with interest (or obsessively notice things that don’t really matter) that the data stored in the table is in YTD format, i.e. it is stored in a cumulative fashion, e.g., January is 1 (and the input number is 1), February is 3 (and the input number is 2), etc. When viewing/loading/inputting data in the Periodic View member – the almost universal view of data in a planning-with-a-small-p application – data is monthly.
Switching quickly back to some semblance of relevance
Let’s send numbers to Final.
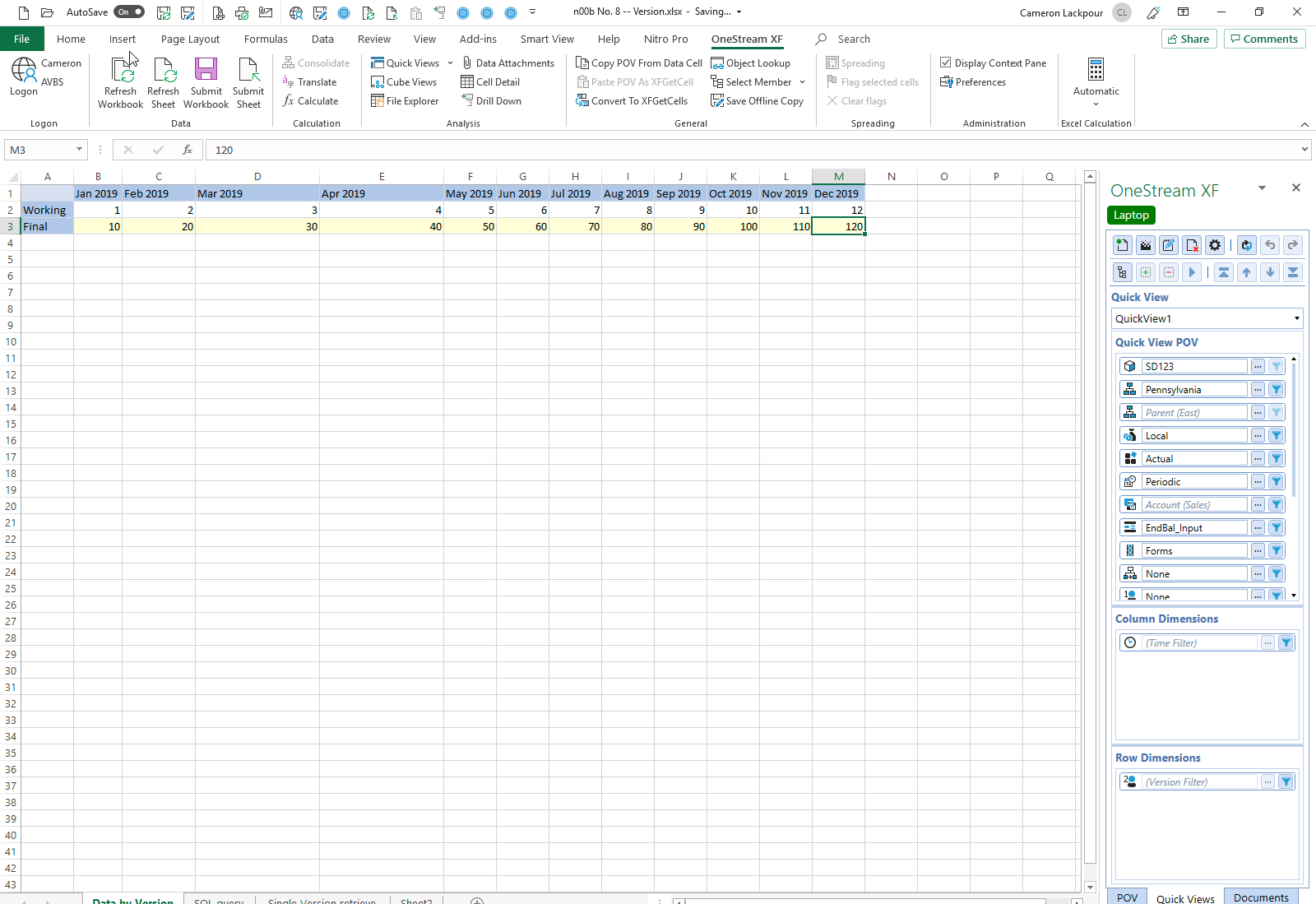
Run that query again and see in a totally unsurprising result two records. Well duh, of course there’s two. So what? Who cares?

We care because every time OneStream processes Cube SD123, the Entity Pennsylvania, the Cons member Local, the Scenario Actual, and the 12 months of the year, OneStream will evaluate the data from two records – both Working and Final.
No worries whatsoever if your code (or data load or whatever) needs to look at both Working and Final but that seems pretty unlikely: it’s going to be one or the other as that is the nature of forecast versions and your process will evaluate all of the records. Don’t think of two records; think of 20,000 or 200,000 or just use your imagination. Really and truly do think of double the numbers because after all Final is just a copy of Working. Remember, big is slow and slow is dead, at least when it comes to performance.
What to do?
Skip the Version dimension. Instead, create two Scenarios: Actual Working and Actual Final – yeah, I know, Actual is a weird choice but I took the screenshots ages ago, deleted the VM that I ran it on, deleted the VM host (yeah, I tried a competitor to VMWare Fusion and found it lacking), am writing this on an aeroplane on a seemingly interminable flight, and am thus for all of these reasons too lazy to go through all of that again. Pretend it’s Forecast. With that design change, when OneStream evaluates Actual (asgain, think Forecast) Working it’s not evaluating Actual Final and vice versa. In the case of this mighty two record application, this design approach has halved the evaluated data on consolidate or Finance Business Rule or Import or Workflow or whatever. Again, apply that thing labelled, “Imagination, For The Use Of”, to a larger application whilst considering the impact of how the Data Unit is processed.
Let me state this again: don’t use a UD to define versions because it will cause OneStream to consider more data than it needs; do use multiple Scenarios because they define multiple Data Units and OneStream will evaluate only the records in a single Data Unit. In this example, Scenario Actual Working is in one Data Unit and Actual Final is in another. And oh yeah, all of this plays quite nicely with Workflow and eleventy million other things in OneStream.
That’s it, but it’s a big deal.
Be seeing you.