Don’t. Don’t do it.
Or at least don’t if you work in a Latin character country like the Good Ol’ U-S-of-A. And it ain’t Unicode, not really, but instead it’s UTF-8. Yr. Obt. Svt. is not going to try to even attempt to explain what UTF-8 is and instead suggests that you enjoy Joel On Software’s explanation. I encourage you to Read The Whole Thing.™ as any blog post that goes into high- and low-endian byte orders has to be good. At least I think so but perhaps I need to get a life. Don’t be intimidated (or bored beyond description) – he really did write an excellent article and I think I almost understand it. Almost.
A note: Planning cloud applications are all Unicode but this is an on-premises tale, even in 2020.
Safely ensconced in the on-premises world (which isn’t going away any time soon I might note), why shouldn’t you create a (not-really) Unicode application? Because this when one tries to import Essbase data (this is on-premises) from a not-really Unicode application to a plain old “normal” one. Bugger. But why?
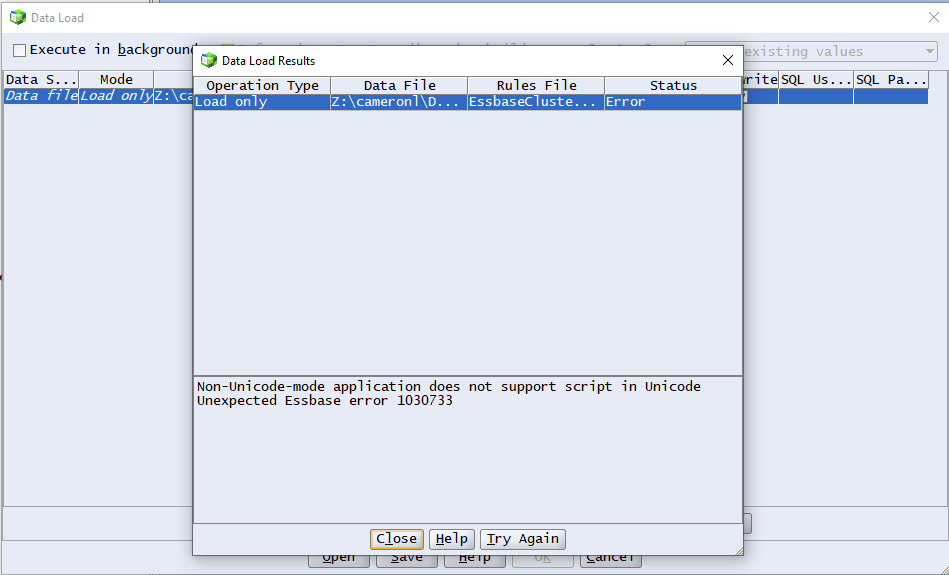
Test was created in Unicode, Development and Production were not. Of course. So when it comes to move data around (think back migration from Test to Development) the wheels fall off.
Somebody did this and that somebody was definitely not a guy named Cameron.
And yet, and yet…Someone Did Just That
But no one will fess up. Here’s The Guilty Consultant before he grew up and made that Planning application Unicode. The path to Ultimate Sin in the form of on-premises Unicode Planning applications starts with small ones, like knocking vases off dressers and then saying, “Not me”. For shame, future Guilty Consultant, for shame.
![]()
Why should I care who did this and why should I call him out? Public shaming is always cruelly fun. I don’t know who you are, Guilty Consultant, but here is your chastisement, because:
![]()
Of course, Nietzsche said, “Distrust all in whom the impulse to punish is powerful” and here I am, punishing away. Can you trust me? Only if I show you every gruesome step. Do I have any other way? Nope.
With the berating and belittling out of the way, can this be fixed?
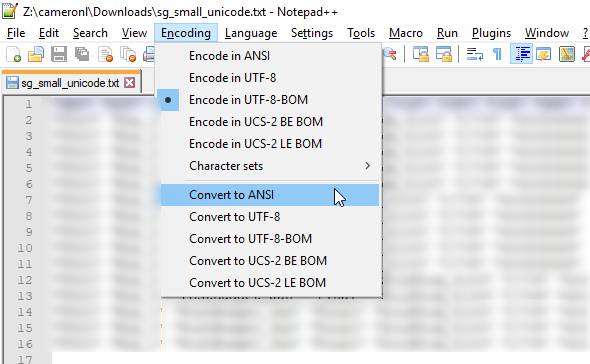
Ah, it needs to be converted to Ascii. I’ve converted UTF-8-BOM (which OMG are commonly referred to as Unicode – I am beginning to understand why Oracle calls it Unicode) Essbase export files to ASCII as contained within ANSI (OMG, again) – via Notepad++.
Bob’s your uncle if you have a small file or even a rather large one. The steps are easy peasy:
- Open the file in this fantastic editor
- Go to the Encoding menu
- Select “Convert to ANSI”
- Notepad++ grinds away for a pleasingly short time
- Save the file as the file can now be loaded into non-Unicode Essbase databases
- Success!
But a big one? 1.3 GB of Unicode badness which is the size of my level 0 column format export? Notepad++ goes KABOOM. I’m pretty sure (actually, quite sure) that it was never designed to perform that kind of conversion. So much for the lazy way for which I am quite well known.
What to do?
“DOS” has the answer. I think.
No, I know, not really DOS but the Windows command shell. Fine. Whatever. It looks like DOS and this is my blog so it’s “DOS”. Sigh, it isn’t. But you get the idea.
It turns out that good old DOS (Hah! Not DOS. I’ll stop with this particular vein.) has the ability to convert from Unicode to ANSI which is as near as damn it to ASCII.
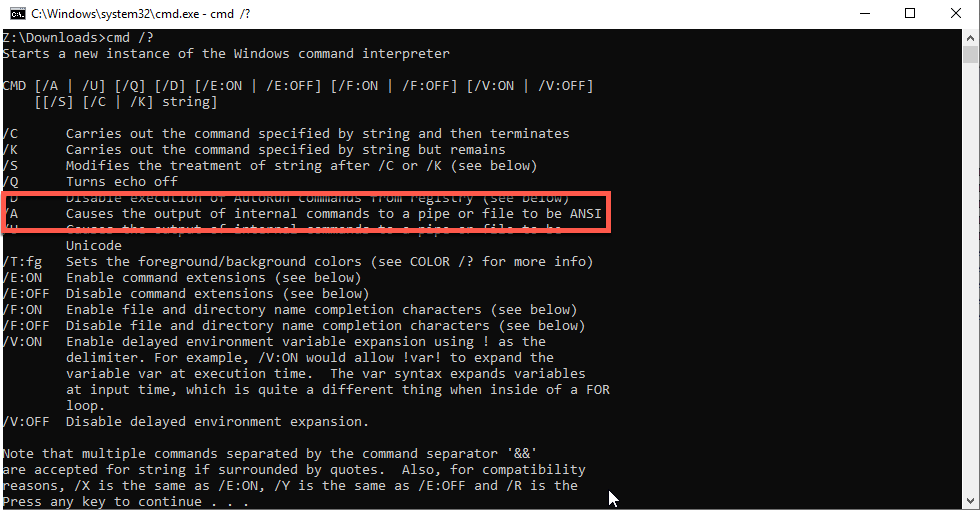
If that’s the case, all I need to do is start up a cmd session that outputs in ANSI and have the cmd shell stop. In other words: cmd /a /c type unicodefile.txt>ansifile.txt
The cmd shell grinds away and “works” but when I tried to load it into Essbase, I received the same Unicode-can’t-work-in-a-non-Unicode-database.
Bugger.
It could be something as simple as missing a switch but I really don’t see where. I wasted an hour with this approach and reluctantly conceded my utter defeat.
So something else?
There are utilities out there that will do the conversion (notably this one) but alas again, the file size gives them agita. There has to be a better way, doesn’t there?
I am nothing if not persistent (also I had no choice so persistence isn’t really the right word – how about desperation) and finally found this: https://www.powershelladmin.com/wiki/Convert_from_most_encodings_to_utf8_with_powershell
Odds bodkins, that’s what I need!
Flipped it from this conversion to UTF8:
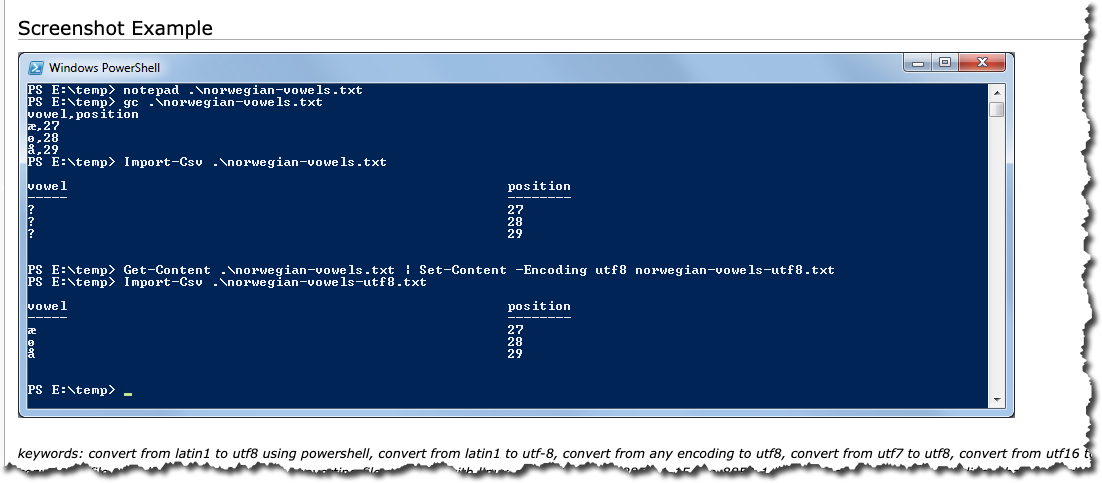
To one that converts to ASCII (which is part of ANSI – my head hurts):
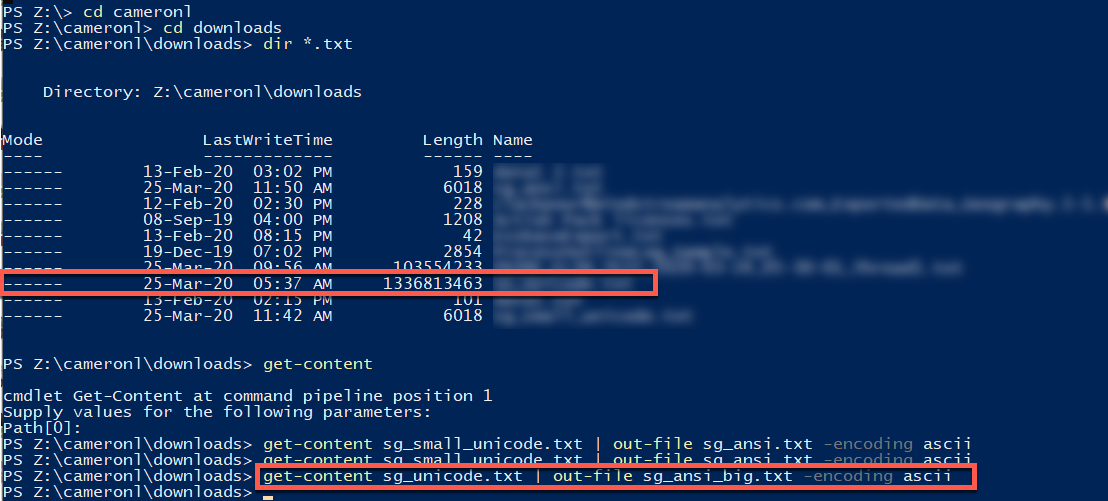
Forgive me typing the first conversion twice – I have no idea why I did that. I was sort of clever enough to try converting and loading that small Unicode file as moving 1.3 GB of data via EAS is not quick via a VPN; I don’t think it’s fast on any kind of connection.
The code within Powershell is simply this:
get-content unicodefile.txt | out-file ansifile.txt -encoding ascii
So easy, even Cameron can do it.
That’s it? That’s it.
Performance was about seven minutes on an 8 GB Win 10 VM running on a Macbook Pro so not the world’s fastest PC. At this point, I didn’t care if it took 70. Hyperbole alert: I would care but it was seven so I don’t care. Whew, this is making me giddy.
That aside, did it work? Did it?
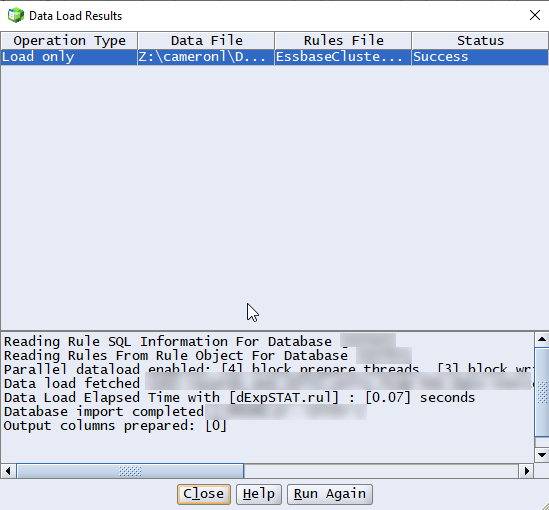
Yes. Yes, it did. Finally.
So that’s all you need: a simple one-line Powershell command that handles those Really Big Files. I cannot believe I didn’t know about it but such are the fortunes of war.
In case any of my vast readership cares, why is this number 31 in my series of Stupid Programming Tricks when there haven’t been any in The Truth About CPM? Easy, it’s because it’s one beyond my last Stupid Trick in the Old Blog.
Be seeing you.
2 thoughts on “Stupid Programming Tricks No. 31 — Have you ever created a Unicode Planning application?”